BNTruster evaluates the "influence" each node in a Bayesian network has on the posterior classification probability. This can be used to calculate the weight of each dataset during Bayesian integration.
Overview
BNTruster offers a collection of ways of evaluating the weight of each node in a Bayesian network. These methods are all variations on determining how much influence each node has on the classification posterior, i.e. how "different" each dataset's probability distributions are for the different class values. Most commonly, this is used to answer the question, "Given a Bayesian classifier that I've learned to integrate many datasets, how much weight is given to each dataset?" If the classifier(s) being evaluated are context-specific, this provides a measure of the functional activity of each dataset within each biological context.
The most principled trust calculation provides, for each dataset, the average weighted change in posterior probability of functional relationship over all values in that dataset. For a dataset D taking one or more discretized values d, this can be written as:
trust(D) = sum( P(D = d) * |P(FR) - P(FR|D = d)|, d in D )
That is, the trust or "influence" of dataset D is the sum over all its values of the probability of that value times the difference in posterior when that value is detected.
Suppose we have two datasets, a microarray dataset MA quantized into five bins and a physical binding dataset PB quantized into two bins. We've learned two context-specific naive Bayesian classifiers for these datasets using BNCreator, one for translation (translation.xdsl) and one for MAPK signaling (mapk.xdsl):
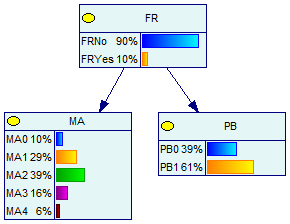
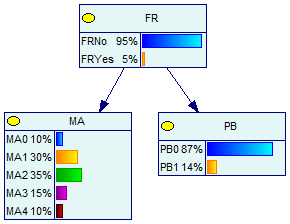
These networks have the following conditional probability tables:
| Translation | |||||
|---|---|---|---|---|---|
| FR | MA | PB | |||
| Value | FR 0 (No) | FR 1 (Yes) | FR 0 (No) | FR 1 (Yes) | |
| 0 | 0.9 | 0.1 | 0.05 | 0.4 | 0.3 |
| 1 | 0.1 | 0.3 | 0.2 | 0.6 | 0.7 |
| 2 | 0.4 | 0.3 | |||
| 3 | 0.15 | 0.3 | |||
| 4 | 0.05 | 0.15 | |||
| MAPK Signaling | |||||
|---|---|---|---|---|---|
| FR | MA | PB | |||
| Value | FR 0 (No) | FR 1 (Yes) | FR 0 (No) | FR 1 (Yes) | |
| 0 | 0.95 | 0.1 | 0.1 | 0.9 | 0.2 |
| 1 | 0.05 | 0.3 | 0.3 | 0.1 | 0.8 |
| 2 | 0.35 | 0.3 | |||
| 3 | 0.15 | 0.2 | |||
| 4 | 0.1 | 0.1 | |||
First, we find the trust of each dataset in the translation-specific network:
trust(MA) = sum( P(MA = d) * |P(FR) - P(FR|MA = d)|, d = 0 to 4 )
= P(MA = 0) * |P(FR) - P(FR|MA = 0)| + ... + P(MA = 5) * |P(FR) - P(FR|MA = 4)|
= 0.095*|0.1 - 0.053| + 0.29*|0.1 - 0.069| + 0.39*|0.1 - 0.077| +
0.165*|0.1 - 0.182| + 0.06*|0.1 - 0.25|
= 0.045
trust(PB) = sum( P(PB = d) * |P(FR) - P(FR|PB = d)|, d = 0 to 1 )
= P(PB = 0) * |P(FR) - P(FR|PB = 0)| + P(PB = 1) * |P(FR) - P(FR|PB = 1)|
= 0.39*|0.1 - 0.077| + 0.61*|0.1 - 0.115|
= 0.018
In the context of translation, the microarray data is somewhat more informative. However, in the MAPK signaling network:
trust(MA) = sum( P(MA = d) * |P(FR) - P(FR|MA = d)|, d = 0 to 4 )
= P(MA = 0) * |P(FR) - P(FR|MA = 0)| + ... + P(MA = 5) * |P(FR) - P(FR|MA = 4)|
= 0.1*|0.05 - 0.05| + 0.3*|0.05 - 0.05| + 0.348*|0.05 - 0.043| +
0.153*|0.05 - 0.066| + 0.1*|0.05 - 0.05|
= 0.0049
trust(PB) = sum( P(PB = d) * |P(FR) - P(FR|PB = d)|, d = 0 to 1 )
= P(PB = 0) * |P(FR) - P(FR|PB = 0)| + P(PB = 1) * |P(FR) - P(FR|PB = 1)|
= 0.865*|0.05 - 0.012| + 0.135*|0.05 - 0.296|
= 0.066
Unsurprisingly (since the example was completely cooked), the process of MAPK signaling is very active in our physical binding dataset.
To have BNTruster do all of this hard work for us, you can just run:
BNTruster translation.xdsl mapk.xdsl
Other trust calculations include sums, calculated as:
trust(D) = sum( |P(D = d|FR) - P(D = d|~FR)|, d in D )
and ratios, calculated as:
trust(D) = log( prod( max{P(D = d|FR), P(D = d|~FR)} / min{P(D = d|FR), P(D = d|~FR)}, d in D ) )
Finally, trust scores can also be calculated for individual bins (i.e. dataset values). These are only available when using the posteriors trust calculation method, and the value represents the fraction of possible change away from prior. Positive values represent an increase from prior to posterior, and negative values a decrease. That is:
trust(d) = ( P(FR|D = d) - P(FR) ) / ( ( P(FR|D = d) > P(FR) ) ? P(~FR) : P(FR) )
Note that this does not incorporate the probability of observing d, i.e. P(D = d).
Usage
Basic Usage
BNTruster <bayesnets.xdsl>*
Writes trust scores (by default, weighted average of difference in posterior) to standard output for all of the (X)DSL files given on the command line.
Detailed Usage
package "BNTruster"
version "1.0"
purpose "Bayes net dataset functional activity evaluation"
section "Optional"
option "type" t "Trust calculation type"
values="posteriors","sums","ratios" default="posteriors"
option "bins" b "Output individual bins"
flag off
option "threads" d "Number of simultaneous threads to use"
int default="1"
option "verbosity" v "Message verbosity"
int default="5"
| Flag | Default | Type | Description |
|---|---|---|---|
| None | None | (X)DSL files | Bayesian networks in which each node's influence on the posterior should be evaluated. |
| -t | posteriors | posteriors, sums, or ratios | Type of trust score to calculate, as described above. |
| -b | off | Flag | If on, output individual bins' influence scores as described above. |
| -d | 1 | Integer | Number of simultaneous threads to use for posterior trust calculations. Threads are per-(X)DSL, so the number of threads actually used is the minimum of -d and the number of input files. |
